[0041] In una incorporazione, il sistema di indicizzazione 110 fornisce tre funzioni primarie operative:
- identificazione di frasi e frasi correlate,
- indicizzazione di documenti con rispetto alle frasi,
- generazione e mantenimento di una tassonomia basata sulle frasi.
Queste abilità valuteranno che il sistema di indicizzazione 110 compierà altre funzioni in supporto delle convenzionali funzioni di indicizzazione.
[0042] 1. L'dentificazione delle frasi
[0043] L'operazione di identificazione della frase del sistema di indicizzazione 110 identifica "buone" o "cattive" frasi nell'insieme di documenti che sono utili per indicizzare e ricercare documenti. In un certo aspetto, le buone frasi sono frasi che occorrono in più di una certa percentuale di documenti nell'insieme di documenti, e/o sono indicati avendo un'apparenza distinta in tali documenti, come delimitato dalle modifiche di tags altri morfologie, formattazione, o indicatori grammaticali. Un'altro aspetto delle buone frasi è che sono premonizioni di altre buone frasi, e non sono soltanto sequenze delle parole che compaiono nel lessico. Per esempio, la frase "presidente degli Stati Uniti" è una frase che predice altre frasi quali "George Bush" e "Bill Clinton". Tuttavia, altre frasi non sono premonitrici, come "cadere dalle nuvole" o "fuori di testa" poiché gli idiomi e i modi di dire come questi tendono a comparire con molte altre frasi differenti e non correlate. Quindi, la fase dell'identificazione della frase determina quali frasi sono buone frasi e quale sono difettose (cioè, difettando nella potenza premonitrice).
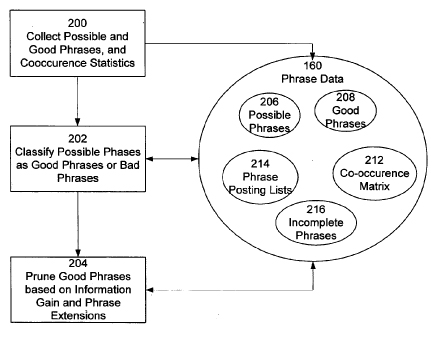 [0044] In riferimento alla fig.1, il processo di identificazione della frase segue i seguenti passi funzionali:
[0044] In riferimento alla fig.1, il processo di identificazione della frase segue i seguenti passi funzionali:
[0045] 200: Raccolta delle possibili buone frasi, con frequenza e co-occorrenza statistica delle frasi.
[0046] 202: Classificazione delle frasi possibili sia come buone o difettose basate sulle statistiche di frequenza.
[0047] 204: Scremare la lista di buone frasi basandosi su una misura preventiva derivata dalle statistiche di co-occorrenza.
[0048] Ciascuna di queste fasi ora sarà descritta con ulteriori dettagli .
[0049] La prima fase 200 è un processo tramite cui il sistema di indicizzazione 110 indicizza un insieme di documenti in una raccolta di documenti, facendo ripetutepartizioni nella raccolta di documenti nel tempo. Una partizione è processata per il passaggio. Il numero di documenti recuperati per passaggio può variare, ed è preferibilmente circa 1.000.000 per partizione. Si preferisce che soltanto i documenti precedentemente non recuperati siano processati in ogni partizione, fino a che non siano processati tutti i documenti, o si incontrino alcuni altri criteri per la terminazione del processo. In pratica, il recupero continua poichè i nuovi documenti sono continuamente aggiunti alla raccolta di documenti. I seguenti passi sono presi dal sistema di indicizzazione 110 per ogni documento che è recuperato.
[0050] Attraversare le parole del documento con una lunghezza della finestra di frase di n, dove la n è una lunghezza massima voluta della frase. La lunghezza della finestra sarà tipicamente almeno 2 e preferibilmente 4 o 5 termini (parole). Le frasi includono preferibilmente tutte le parole nella finestra di frase, comprese quelle che in altri modi sarebbero considerato stop words, come "un" "il" e così via. Una finestra di frase può essere terminata da una conclusione della linea, un ritorno di paragrafo, un tag, o altri indizi di un cambiamento nel contenuto o formato.

[0051] La figura 2 illustra una parte di un documento 300 durante un attraversamento del processo di recupero, mostante la finestra di frase 302 che comincia alla parola "razza" e che si estende di 5 parole verso la destra. La prima parola nella finestra di frase 302 è la frase candidata i, e ciascuna delle sequenze i+1, i+2, i+3, i+4 e i+5 è similarmente una frase candidata. Quindi, in questo esempio, le frasi candidate sono: "razza", "cani di razza", "cani di razza per", "cani di razza per", "cani di razza per i baschi" e "cani di razza per i pastori baschi".
[0052] In ogni finestra di frase 302, ogni frase candidata è controllata a sua volta per determinare se è già presente nella buona lista di frasi 208 o nella lista di frasi possibili 206 . Se la frase candidata non è presente sia nella buona lista 208 o nella lista possibile 206, allora la frase candidata è stata già determinata per essere "cattiva" eviene saltata.
[0053] Se la frase candidata è nella buona lista 208, come entrata gj allora la voce di indice 150 per la frase gj è aggiornata per includere il documento (per esempio, il relativo URL o altro identificativo del documento), per indicare che questa frase candidata gj compare nel documento corrente. Un'entrata nell'indice 150 per una frase gj (o un termine) è riferita come la "posting list" della frase gj . La "posting list" include una lista dei documenti d (dai loro identitificativi, per esempio un numero di documento, o alternativamente un URL) in cui la frase si presenta.
[0054] In più, la matrice di co-occorrenze 212 è aggiornata, come ancora spiegato sotto. Nel primissimo passaggio, le buone e le cattive liste saranno vuote e così, la maggior parte delle frasi tenderanno ad essere aggiunte alla lista di frasi possibili 206.
[0055] Se la frase candidata non è nella buona lista 208 allora è aggiunta alla lista possibile 206, a meno che non sia già presente. Ogni entrata p sulla lista di frasi possibili 206 ha tre conteggi associati:
[0056] P(p): Numero di documenti su cui la frase possibile compare;
[0057] S(p): Numero di tutti i casi della frase possibile;
[0058] M(p): Numero di casi interessanti della frase possibile. Un caso di una frase possibile è "interessante" dove la frase possibile è distinta dal contenuto limitrofo nel documento tramite indicatori grammaticali o di formattazione, per esempio essendo in grassetto, o sottolineate, o come anchor text di un link, o tra virgolette. Queste (ed altre) distinzioni di apparenza sono indicate dalle varie modifiche fornite con i tag HTML e dagli indicatori grammaticali. Queste statistiche sono effettuate per una frase quando è disposta sulla buona lista 208.
[0059] In addizione alle varie liste, è mantenuta una matrice delle co-occorrenze 212 (G) per le buone frasi. La matrice G ha dimensioni m x m, dove m è il numero delle buone frasi. Ogni elemento G(j,k) nella matrice rappresenta un paio di buone frasi ( gj , gk ). La matrice 212 mantiene logicamente tre conti separati per ogni paio ( gj , gk ) di buone frasi in rispetto ad una finestra secondaria 304 che è incentrata sulla parola corrente i, e si estende di +/- h parole. In un esempio, come in fig.3, la finestra secondaria 304 è di 30 parole ( i+30, i-30 ). La matrice delle co-occorrenze 212 mantiene:
[0060] R(j,k) Conteggio delle righe co-occorrenti. Il numero delle volte che la frase gj appare in un finestra secondaria 304 con la frase gk.
[0061] D(j,k) Conteggio interessante disgiunto. Il numero delle volte che ogni frase gj o gk appare come testo distinto nella finestra secondaria.
[0062] C(j,k) Conteggio interessante congiunto. Il numero di volte che sia le frasi gj che gk appaiono come testo distinto nella finestra secondaria. L'uso di questo conteggio è particolarmente utile per evitare le circostanze dove la prase (ad esempio: nota di copyright) appare frequentemente nelle barre laterali, nel footer o nell'header, a questa non ha poteri di predizione di altro testo.
[0063] In riferimento all'esempio di fig.2, assumiamo che "cani di razza" è nella buona lista di frasi 208, così come le frase "pastore australiano" e "pastore australiano Club dell'America". Entrambi queste frasi compaiono nella finestra secondaria 304 intorno alla frase corrente "cani di razza". Comunque, la frase "pastore australiano Club dell'America" compare come anchor text di un link (indicato dalla sottolineatura) verso un sito web. Così il conteggio della riga co-occorrente per la coppia "cani di razza" "pastore australiano" viene incrementato, e il conteggio di riga e quello di interesse disgiunto per "cani di razza" "pastore australiano Club dell'America" sono entrambi incrementati visto che le frasi posteriori compaiono come testo distinto.
 |
|  |
|  |
|  |
|  |
|  |
|  |
|  |
|  |
|  |
| 
Posted in Phrase based searching in IRS printer-friendly version | 4555 reads
Submitted by Motori-e-Ricerca on Tue, 2007-05-08 13:42.